

根据最新披露的信息,OpenAI 的一款内部实验性大语言模型在模拟 2025 年国际数学奥林匹克竞赛(IMO)中取得了金牌水平的成绩,以 35/42 的得分(满分 42 分)达到金牌标准(2024 年金牌分数线为 32 分)。这一突破标志着 AI 在复杂数学推理领域的重大进展,其意义远超传统基准测试,因为 IMO 被公认为衡量创造性数学思维的巅峰挑战。

一、测试环境与评分标准
此次实验严格复现了 IMO 的真实竞赛条件:
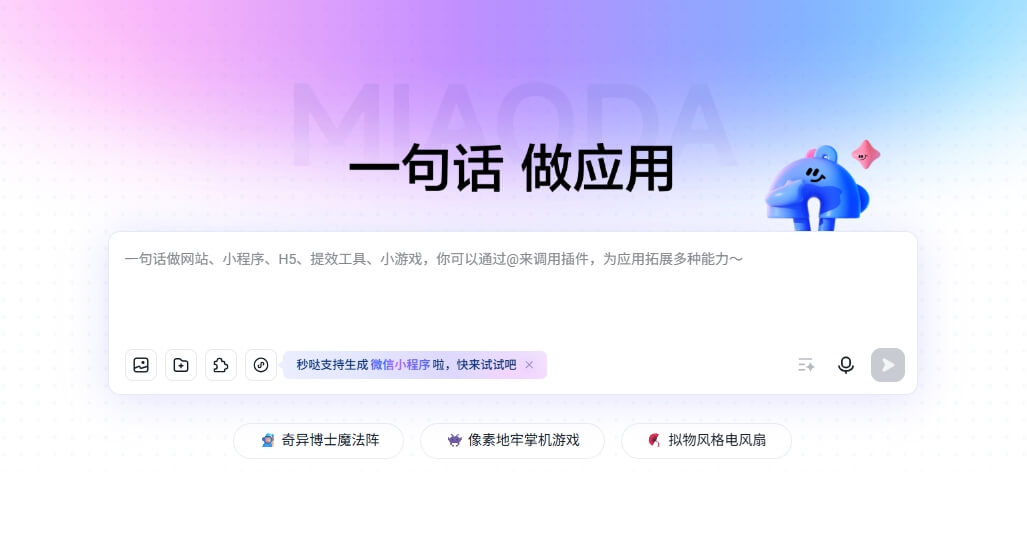
- 时间约束:模型需在两场各 4.5 小时的考试中完成 6 道原创证明题,平均单题耗时约 100 分钟,远超常规 AI 任务(如 GSM8K 单题仅需 0.1 分钟)。
- 工具限制:全程闭卷,禁用计算工具、形式化验证器(如 Lean),仅通过自然语言推导生成多页严谨证明。
- 模糊评估:答案需由三位前 IMO 奖牌得主独立评审,重点考察证明的逻辑连贯性和创新性,而非单一数值结果。
最终,模型成功解决了前 5 道题(P1-P5),第六题因涉及高维几何与博弈论的交叉领域(全球仅 6 人在真实竞赛中解出)未能突破。
二、技术突破与训练方法
该模型的核心进展体现在通用推理能力的根本性提升,而非针对 IMO 的专项优化:
- 超长思维链构建:模型通过强化学习和动态规划技术,将推理时长从分钟级(如 MATH 基准)扩展至小时级,能够在复杂问题中自主规划多步骤验证路径。
- 无监督证明生成:采用「生成 – 验证」双循环架构,先通过语言模型生成候选证明,再利用符号逻辑引擎验证每一步的数学严谨性,最终形成可被人类专家认可的论证体系。
- 跨领域迁移能力:训练数据涵盖科学文献、代码库和数学竞赛题,但未包含 2025 年 IMO 真题。其解题能力源于对抽象数学结构的泛化理解,而非记忆特定题型。
OpenAI 研究团队特别强调,这一成果验证了计算扩展与通用 AI 结合的潜力。例如,模型在测试时通过动态分配计算资源(如增加 token 生成步数),显著提升了复杂问题的解决效率,这与传统依赖预训练参数规模的路径截然不同。
未经允许不得转载:墨鱼导航 » OpenAI内部实验性大语言模型模拟2025年IMO竞赛获金牌水平成绩

















评论 ( 0 )