

2025 年 5 月,Meta 推出了 KernelLLM。这是一个基于 Llama 3.1 Instruct 进行微调的 8B 参数模型,旨在将 PyTorch 模块自动转换为高效的 Triton GPU 内核。

以下是关于它在 GPU 内核生成领域性能超越 GPT – 4o 的具体介绍:
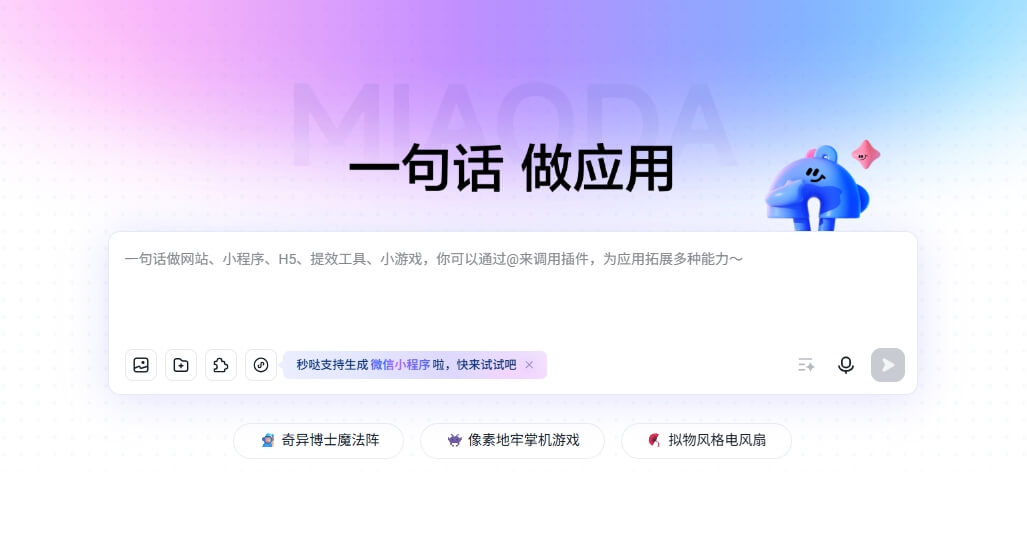
- 测试得分:在 KernelBench – Triton 测试中,8B 参数的 KernelLLM 单次推理得分 20.2,而 200B 参数的 GPT – 4o 得分仅为 15 分,671B 参数的 DeepSeek V3 得分为 16 分。如果进行多次推理,KernelLLM 生成 10 个候选代码时得分为 51.8 分,生成 20 个时得分为 57.1 分,性能优势更加明显。
- 测试环境:所有测试都在 NVIDIA H100 GPU 上完成。
- 模型优势:KernelLLM 用更少的参数实现了更强的性能,且简单易用。它是首个在外部(PyTorch,Triton)代码对数据上进行微调的 LLM,能让 GPU 编程变得更简单,实现高性能 GPU 内核生成的自动化,满足对高性能 GPU 内核日益增长的需求。
KernelLLM 的训练使用了 25000 多对(PyTorch,Triton)代码示例以及合成的样本,采用标准监督微调(SFT)方法,在 16 个 GPU 上训练 10 个 epoch,耗时 12 小时。通过在 KernelBench – Triton 基准测试上的出色表现,证明了其在生成高效 Triton GPU 内核方面的卓越能力,为 GPU 内核开发提供了更强大、更便捷的工具1。
未经允许不得转载:墨鱼导航 » Meta推出8B参数KernelLLM,在GPU内核生成领域性能超越GPT-4o

















评论 ( 0 )